Онлайн извличането ви позволява да събирате отворени данни от уебсайтове за цели като сравнение на цени, проучване на пазара, проверка на реклами и др.
Обикновено се извличат големи количества от необходимите публични данни, но когато работите срещу блокади, извличането може да стане предизвикателство.
Ограничението може да бъде или блокиране на скоростта, или блокиране на IP (IP адресът на заявката е ограничен, защото произхожда от забранена зона, забранен тип IP и т.н.). (IP адресът е блокиран, защото е направил множество заявки).

Сега, ако сте готови да изчерпите някои полезни знания и информация, тогава съм сигурен, че трябва да сте обмислили да изчерпите Wikipedia, енциклопедията на знанието, която е дом на тонове информация.
Нека разберем няколко неща относно уеб скрапинга на Wikipedia.
Wikipedia Web Scraping
Уеб сканирането е автоматизиран метод за събиране на данни от интернет. В тази статия е предоставена задълбочена информация за уеб скрапинга, сравнение с уеб обхождането и аргументи в полза на уеб скрапинга.
Целта е да се съберат данни от началната страница на Wikipedia, като се използват различни методи за уеб скрапинг, след което да се анализират.
Ще се запознаете по-добре с различни методи за уеб скрапинг, библиотеки за уеб скрапиране на Python и процедури за извличане и обработка на данни.
Уеб скрапинг и Python
Уеб скрапингът е по същество процесът на извличане на структурирани данни от голямо количество данни от голям брой уебсайтове с помощта на софтуер, който е създаден на език за програмиране и го запазва локално на нашите устройства, за предпочитане в таблици на Excel, JSON или електронни таблици.
Това помага на програмистите да създават логичен, разбираем код както за малки, така и за големи проекти.
Python се счита предимно за най-добрия език за уеб скрапинг. Той може ефективно да се справи с повечето задачи, свързани с обхождането на мрежата, и е по-скоро универсален.
Как да изгребвам данни от Wikipedia?
Данните могат да бъдат извлечени от уеб страници по различни начини.
Например, можете да го внедрите сами, като използвате компютърни езици като Python. Но освен ако не сте технически разбиращ, ще трябва да проучите много, преди да можете да направите много с този процес.
Освен това отнема време и може да отнеме толкова време, колкото ръчното прелистване на страниците на Wikipedia. Освен това безплатните уеб скрепери са достъпни онлайн. И все пак често им липсва надеждност и техните доставчици може да имат тъмни намерения.
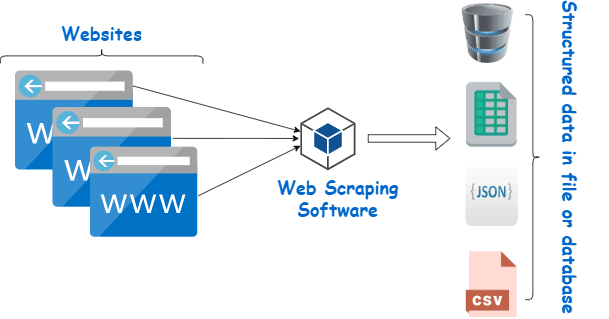
Инвестирането в приличен уеб скрепер от реномиран доставчик е най-добрият метод за събиране на Wiki данни.
Следващата стъпка обикновено е проста и неусложнена, защото доставчикът ще ви предложи инструкции как да инсталирате и използвате скрепера.
Проксито е инструмент, който можете да използвате заедно с вашия wiki scraper за по-ефективно изчерпване на данни. Базирани на Python рамки като Scrapy, Остъргващ робот, и Beautiful Soup са само няколко примера за това колко лесно е да се изгребва с помощта на този език.
Прокси за изчерпване на данни от Wikipedia
Нуждаете се от прокси сървъри, които са изключително бързи, безопасни за използване и гарантирано няма да ви нападнат, когато имате нужда от тях, за да изтриете данните ефективно. Такива проксита се предлагат от Rayobyte на разумна цена.
Полагаме усилия да предлагаме разнообразие от проксита, защото сме наясно, че всеки потребител има различни предпочитания и случаи на употреба.
Въртящи се прокси сървъри за уеб сканиране на Wikipedia
Екземпляр на прокси е този, който редува IP адреса си редовно. Освен това, за да се предотвратят прекъсвания, IP адресът се променя незабавно, когато възникне забрана. Това прави този конкретен прокси чудесен избор за сканиране на сайтове.
За сравнение статичните проксита имат само един IP адрес. Ако вашият интернет доставчик не активира автоматизирани замествания, ще се натъкнете на тухлена стена, ако имате достъп само до един IP адрес и той бъде блокиран. Поради това статичните прокси сървъри не са най-добрият вариант за уеб сканиране.
Жилищни прокси сървъри за уеб сканиране на Wiki данни
Местните проксита са прокси IP адреси, които доставчиците на интернет услуги (ISP) разпространяват и са свързани с конкретни домакинства. Тъй като идват от реални хора, получаването им е доста предизвикателство. В резултат на това те са оскъдни и сравнително скъпи.

Когато използвате домашни прокси сървъри за изчерпване на данни, изглежда, че сте обикновен потребител, защото те са свързани с адресите на реални лица.
Така че използването на домашни проксита значително намалява шанса ви да бъдете открити и блокирани. Следователно те са отлични кандидати за извличане на данни.
Ротационни местни проксита за събиране на wiki данни
Въртящият се прокси сървър, който съчетава двата типа, за които току-що говорихме, е най-добрият прокси за уеб сканиране на Wikipedia.
Можете да получите достъп до голям брой домашни IP адреси, като използвате прокси, който ги сменя често.
Това е от решаващо значение, защото въпреки трудността при идентифициране на местни проксита, обемът на заявките, които те генерират, в крайна сметка ще привлече вниманието на уебсайта, който се изтрива.
Ротацията гарантира, че проектът може да продължи, дори ако IP адресът неизбежно попадне в черния списък.
Следователно ние разполагаме с това, от което се нуждаете, независимо дали решите да използвате няколко проксита в центъра за данни или предпочитате да инвестирате в няколко домашни проксита.
Ще се насладите на най-доброто изживяване при сканиране на уеб с прокси сървъри, работещи със скорост 1GBS, неограничена честотна лента и денонощно обслужване на клиенти.
Може и да четете
- Най-добри техники за уеб скрапиране: Практическо ръководство
- Преглед на Octoparse Наистина ли е добър инструмент за уеб скрапиране?
- Най-добрите инструменти за уеб скрапиране
- Какво е уеб скрапинг? - Как се използва? Как може да е от полза за вашия бизнес
Защо трябва да изтривате Wikipedia?
Wikipedia е една от най-доверените и богати на информация услуги в онлайн света в момента. В тази платформа има отговори и информация на почти всички видове теми, за които можете да се сетите.
Така че, естествено, Wikipedia е чудесен източник за изчерпване на данни. Нека обсъдим основните причини, поради които трябва да изтриете Wikipedia.
Уеб скрапинг за академични изследвания
Събирането на данни е една от най-болезнените дейности, свързани с изследването. Както вече беше обсъдено, уеб скреперите правят тази процедура по-бърза и лесна, като същевременно ви спестяват много време и енергия.
С уеб скрепер можете бързо да сканирате множество уики страници и да съберете всички необходими данни по организиран начин.
Приемете за момент, че целта ви е да определите дали депресията и излагането на слънчева светлина варират според страната.
Можете да използвате Wiki scraper, за да намерите информация като разпространението на депресията в различните нации и техните слънчеви часове, вместо да преглеждате множество записи в Wikipedia.
Управление на репутацията
Създаването на страница в Wikipedia се е превърнало в задължителна маркетингова стратегия за много различни видове бизнес в съвременната епоха, тъй като публикациите в Wikipedia често се появяват на първата страница на Google.
Но наличието на страница в Wikipedia не трябва да е краят на вашите маркетингови усилия. Уикипедия е а crowd-sourced платформа, така че вандализмът е нещо, което се случва доста често.
В резултат на това някой може да добави неблагоприятна информация към страницата на вашата компания и да навреди на репутацията ви. Като алтернатива те могат да оклеветят вашия бизнес в подходяща wiki статия.
Поради това трябва да следите вашата Wiki страница, както и други страници, които споменават вашия бизнес, след като бъде създаден. Можете да направите това с помощта на wiki scraper с лекота.
Можете периодично да търсите в страниците на Уикипедия за препратки към вашия бизнес и да посочвате всякакви случаи на вандализъм там.
Увеличете SEO
Можете да използвате Wikipedia, за да увеличите трафика към уебсайта си.
Създайте списък със статии, които искате да промените, като използвате Wiki скрепер за данни, за да намерите страници, които са подходящи за вашия бизнес и вашата целева аудитория.
Започнете, като прочетете статиите и направите няколко полезни корекции, за да спечелите доверие като сътрудник на сайта.
След като установите известно доверие, можете да добавите връзки към уебсайта си на места, където има повредени връзки или където се изискват цитати.
Бързи връзки
Библиотеки на Python, използвани за уеб скрапинг
Python е най-популярният и уважаван език за програмиране и инструмент за уеб сканиране в света, както вече беше казано. Сега нека да разгледаме библиотеките за уеб скрапиране на Python, които са налични в момента.
Библиотека с заявки (HTTP за хора) за уеб скрапинг
Използва се за изпращане на различни HTTP заявки, като GET и POST. Сред всички библиотеки тя е най-основната, но и най-важната.
lxml библиотека за уеб скрапинг
Пакетът lxml предлага много бързо и високопроизводително анализиране на HTML и XML текст от уебсайтове. Това е този, който трябва да изберете, ако възнамерявате да изстържете огромни бази данни.
Красива супена библиотека за уеб скрапинг
Неговата работа е изграждането на дърво за анализ на съдържанието. Страхотно място за начало за начинаещи и е изключително удобно за потребителя.
Библиотека Selenium за уеб скрапинг
Тази библиотека решава проблема, който имат всички библиотеки, споменати по-горе, а именно изтриване на съдържание от динамично попълвани уеб страници.
Първоначално е проектиран за автоматизирано тестване на уеб приложения. Поради това той е по-бавен и неподходящ за задачи на индустриално ниво.
Scrapy за уеб скрапинг
Пълна рамка за уеб скрапинг, която използва асинхронно използване е ШЕФЪТ на всички пакети. Това повишава ефективността и го прави светкавично бърз.
Заключение
Така че това беше почти най-важният аспект, който трябва да знаете за Wikipedia Web Scraping. Останете на линия с нас за още такива информативни публикации относно Web Scraping и много повече!
Бързи връзки


