Letar efter en opartisk Bright Data Scraping Browser Review, Oroa dig inte, jag har täckt dig.
Dataskrapning är ett viktigt verktyg för företag och forskare att extrahera värdefulla insikter från internet.
Det kan dock vara en utmanande och tidskrävande uppgift, särskilt när man hanterar komplexa webbplatser som använder botdetekteringssystem och webbplatsblockeringar.
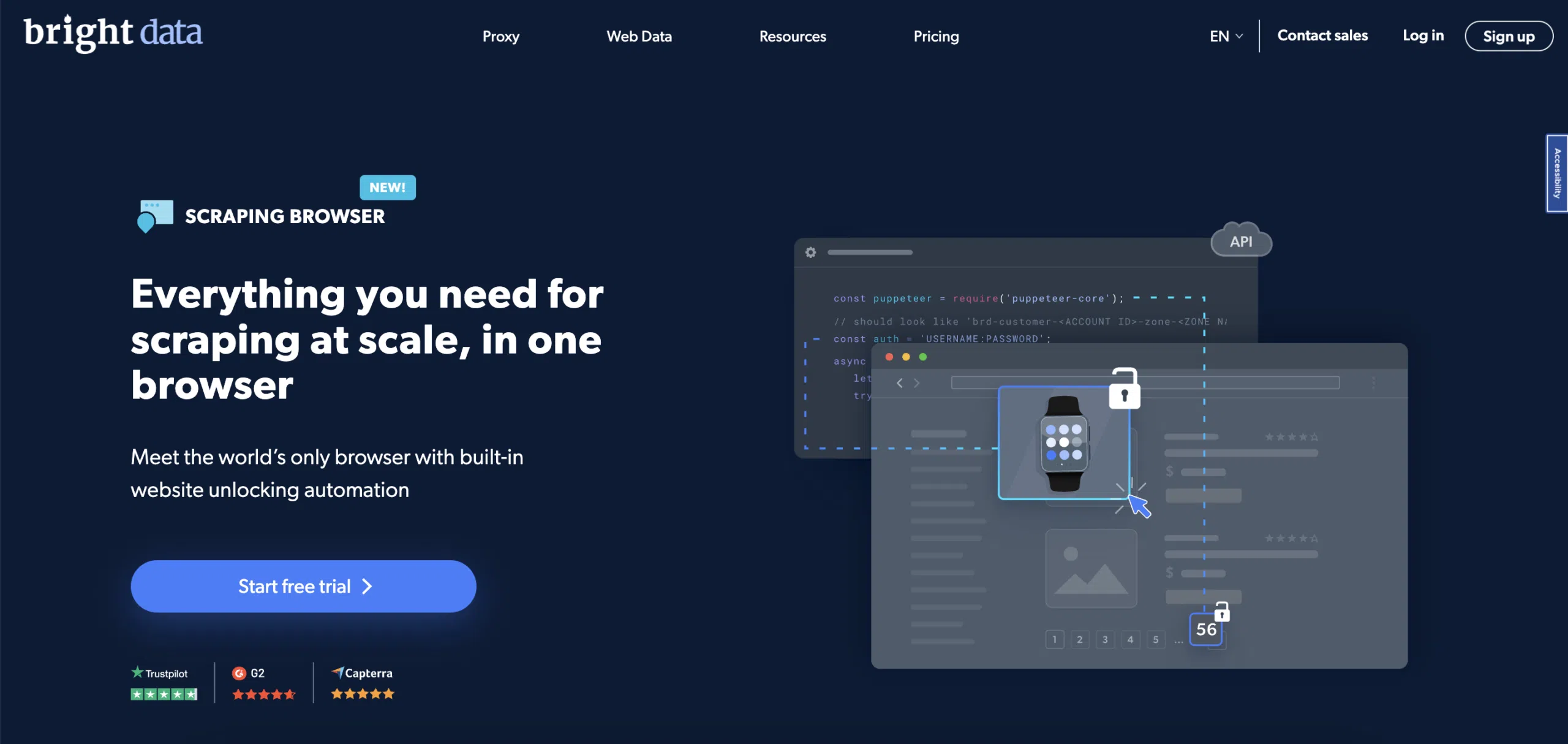
Bright Data Scraping Browser är en allt-i-ett automatisk webbläsare utformad speciellt för dataskrapningsändamål.
I den här artikeln kommer vi att granska nyckelfunktioner och fördelar of Bright Data Scraping Browser och förklara varför det är ett tillförlitligt verktyg för dataskrapningsprojekt.
Oavsett om du är ett litet företag eller ett stort företag, hjälper den här recensionen dig att avgöra om Bright Data Scraping Browser är det rätta verktyget för dina dataskrapningsbehov.
Vad är scraping webbläsare och varför använda dem?

En scraping-webbläsare är en webbläsare som körs automatiskt och som används av kodare för att hämta data. Det kan hanteras av API:er på hög nivå som Dockspelare och dramatiker, och den har inbyggda funktioner för att avblockera webbplatser.
Till skillnad från tomma webbplatser har en scraping-webbläsare en grafiskt användargränssnitt (GUI) som låter dig bestämma hur det fungerar.
När de skrapar data använder utvecklare automatiska webbläsare när en sida behöver renderas i JavaScript eller de behöver ansluta till en webbplats.
Till exempel, flytta, byta sida, klicka och till och med ta skärmdumpar. Dessutom kan webbläsare hjälpa till med storskaliga dataskrapningsprojekt som riktar sig till flera sidor samtidigt.
Scraping Browser är ett mycket bättre sätt att skala dataskrapningsprojekt och komma runt block än tomma webbläsare. Huvudlösa webbläsare är webbläsare som inte har ett synligt användargränssnitt.
Dessa webbläsare används ofta med proxyservrar för att skrapa data, men bot-skyddsprogram kan lätt upptäcka dem. Detta gör det svårt att skrapa data i stor skala.
Det faktum att Scraping Browser öppnas på Bright DataÄr datorer är en annan fördel. Detta gör den perfekt för projekt som behöver skalas upp.
Utvecklare kan öppna så många Scraping-webbläsare som de vill utan att behöva betala för ett dyrt system på sina egna datorer.
Dessutom är det mindre sannolikt att Scraping Browser hittas av programvara som letar efter bots eftersom den har ett GUI-gränssnitt. Detta gör det till ett mer pålitligt verktyg för skrapa data.


Bright Data Scraping-webbläsare och köpguide
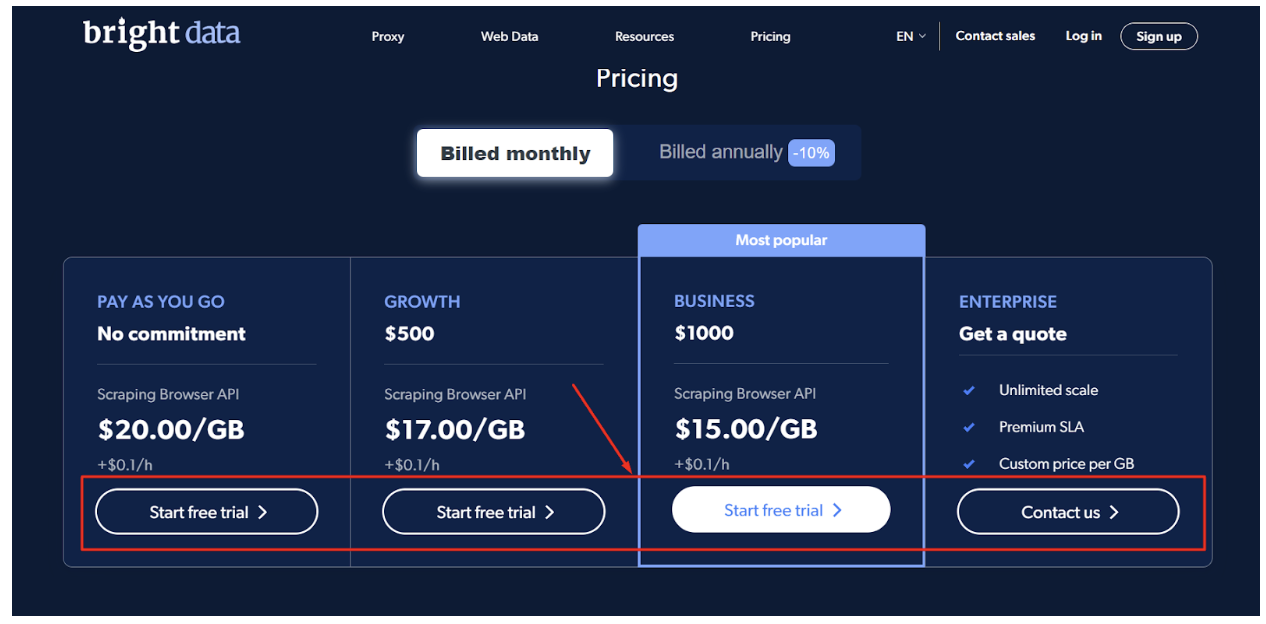
Steg - 1: Gå till officiell webbplats för Bright Data Skrapande webbläsare, scrolla ned och välj den plan du väljer.
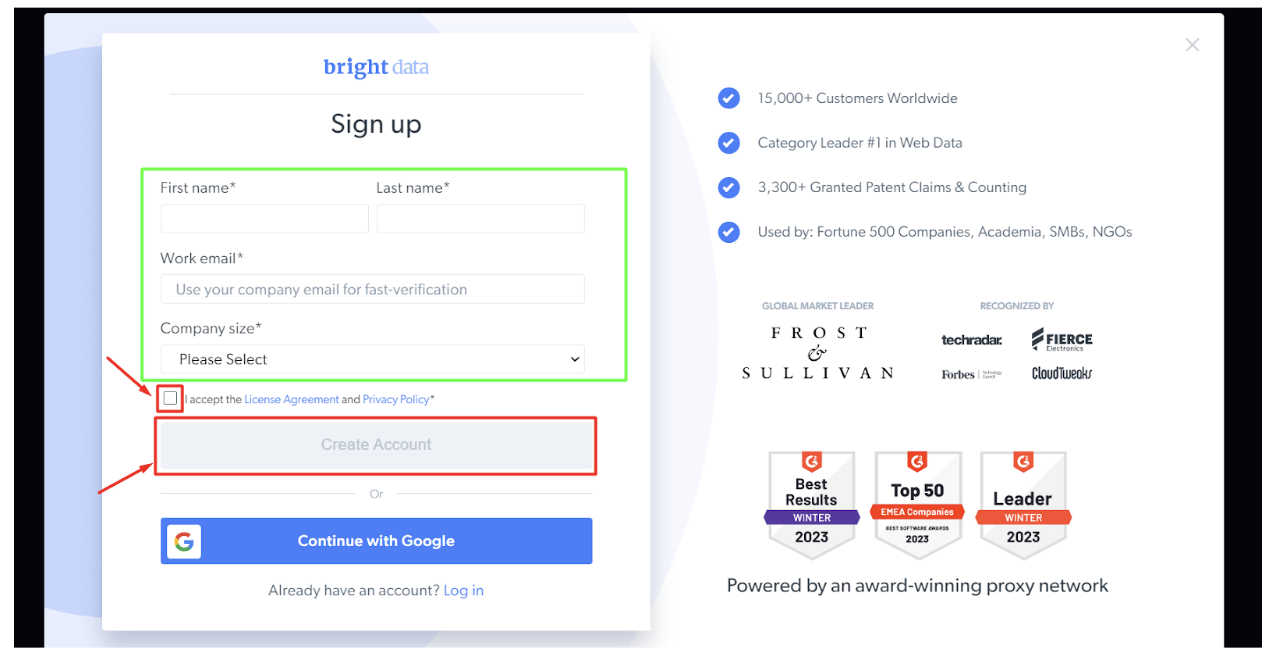
Steg - 2: Fyll i de begärda uppgifterna, markera rutan och klicka på "Skapa konto".
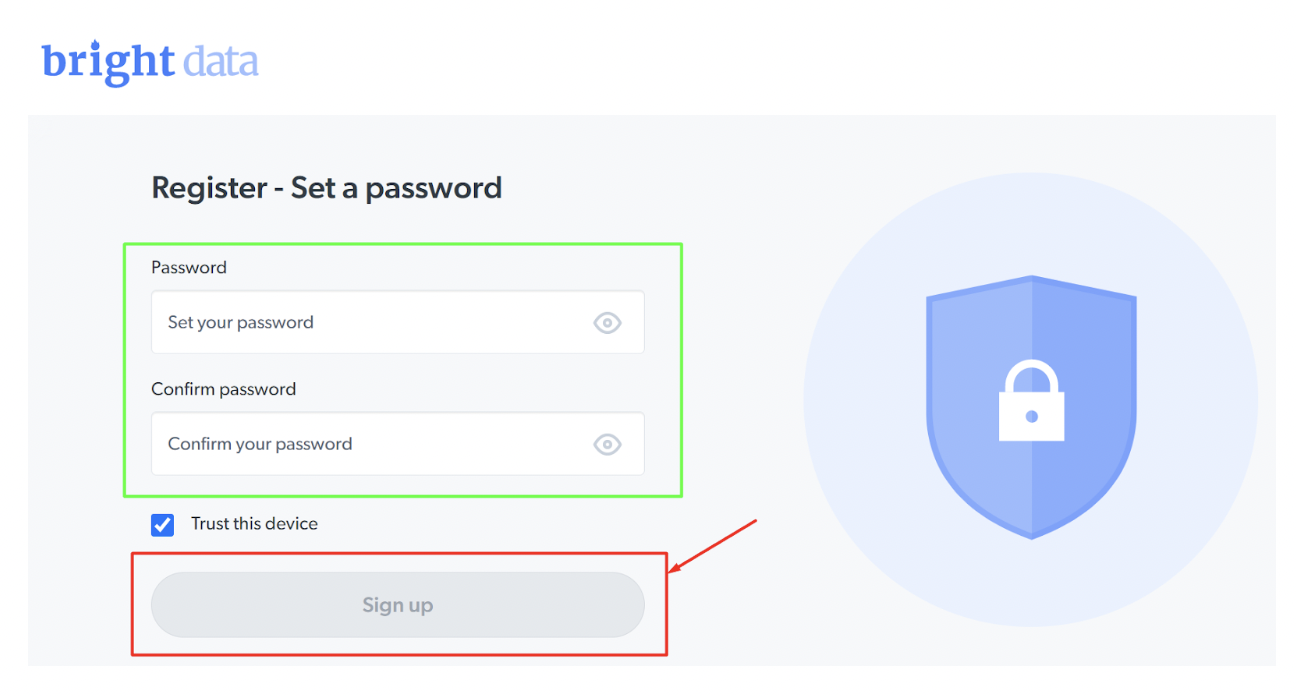
Steg - 3: Fyll i uppgifterna och klicka på "Registrera dig".
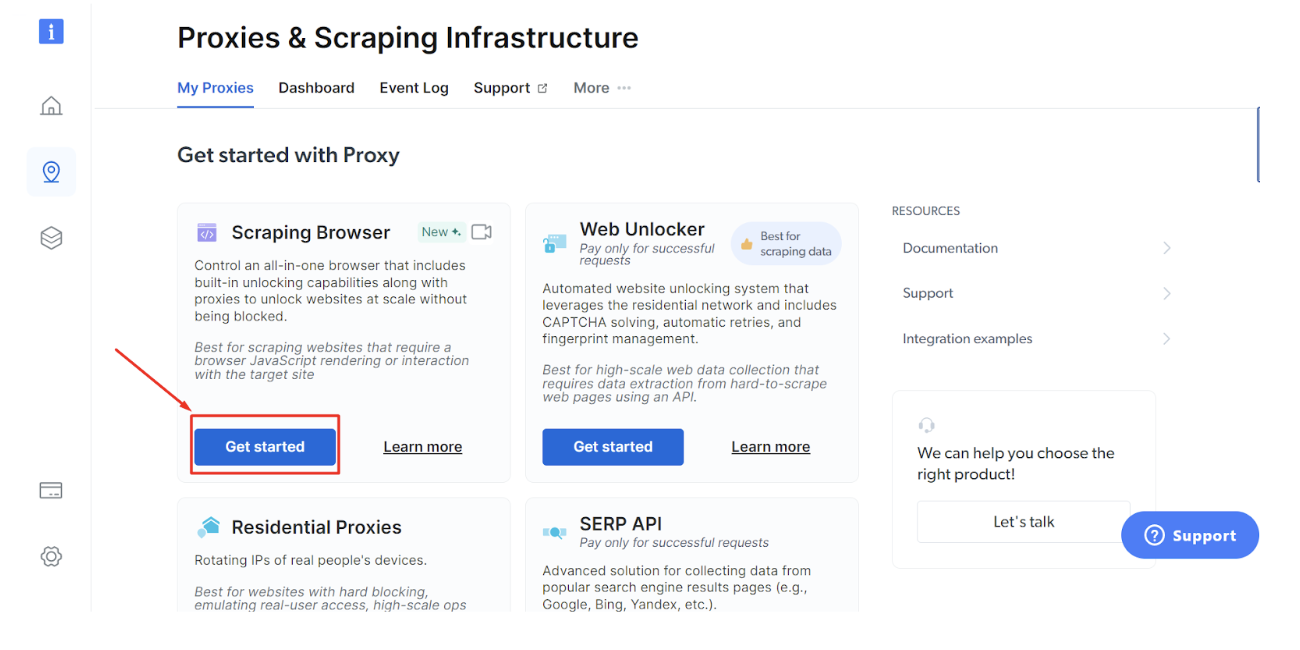
Steg - 4: Klicka på "Kom igång" nedan Bright Data Skrapande webbläsare.
Steg - 5: Klicka på "Spara och aktivera".

Steg - 6: Fyll i faktureringsinformationen och klicka på "Spara adress".
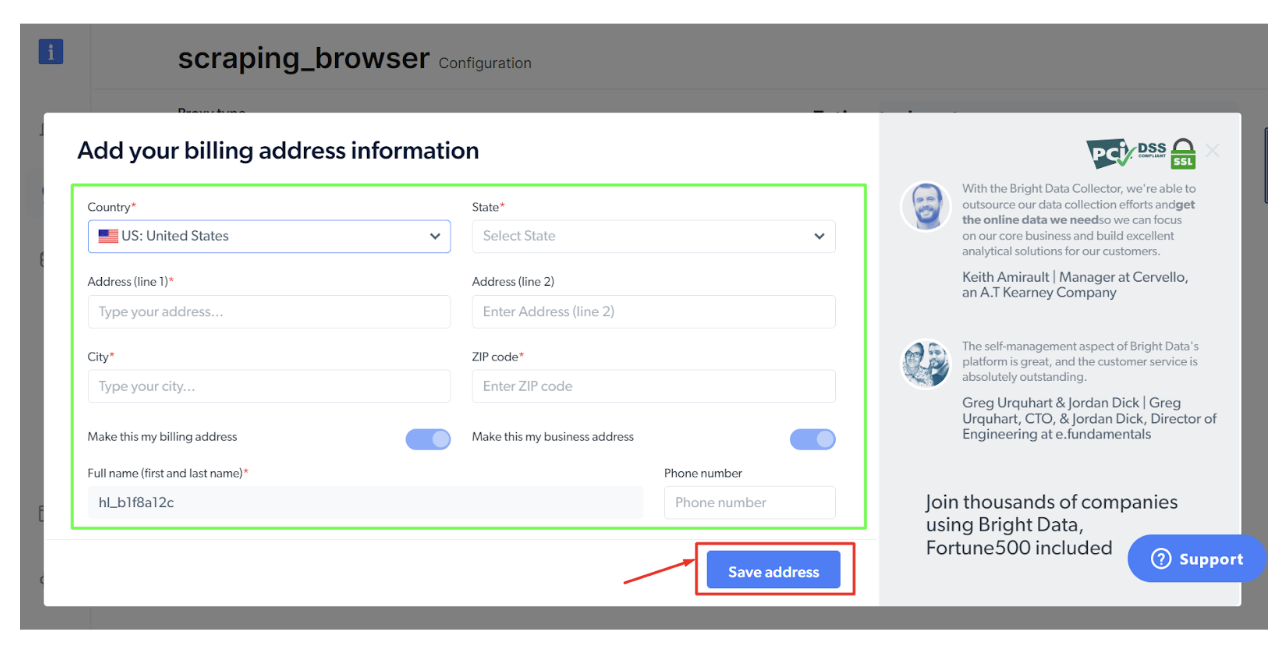
Slutför betalningen och du är klar.
Varför rekommenderar jag att använda Bright Data Skrapa webbläsaren?
Bright Data Scraping Browser är en automatisk webbläsare designad speciellt för dataskrapningsändamål. Här är några anledningar till varför jag rekommenderar att du använder den här webbläsaren dataskrapningsprojekt:
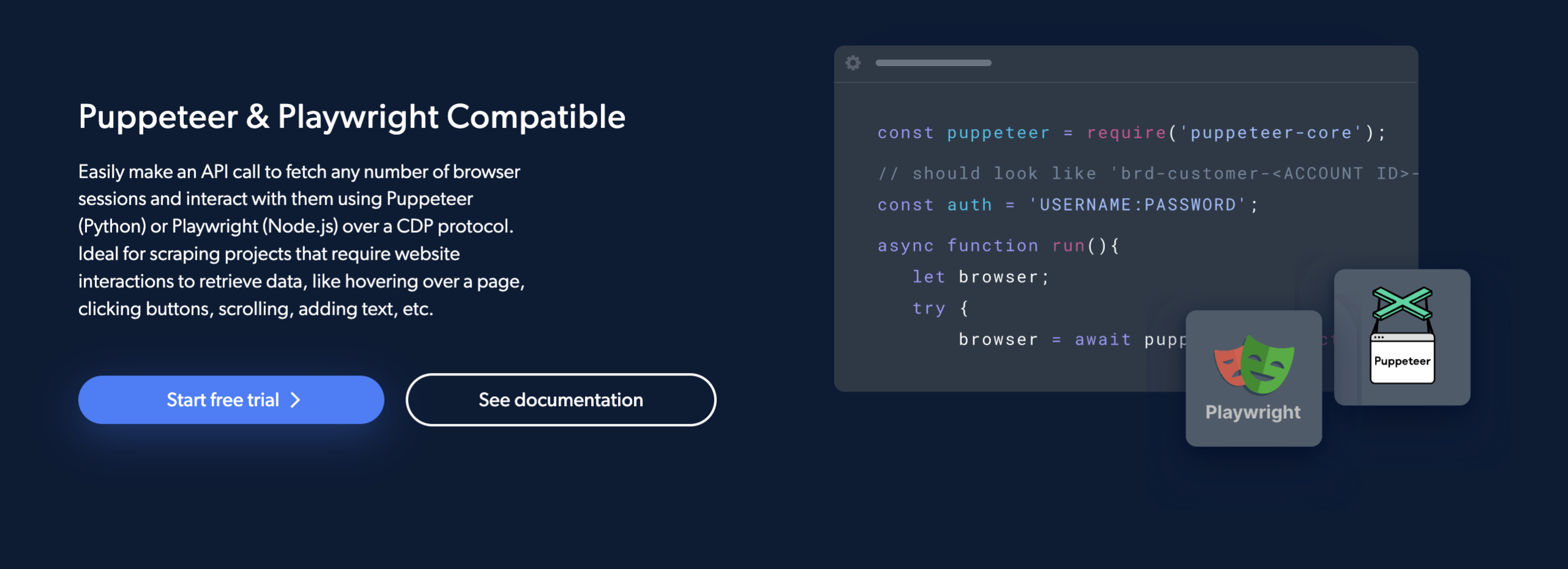
1. Kompatibel med dockspelare och dramatiker:
Bright Data Scraping Browser fungerar med både Puppeteer (Python) och Playwright (Node.js), som är två populära API:er för att automatisera dataskrapning.
Detta gör det enkelt för kodare att få valfritt antal webbläsarsessioner och arbeta med dem med hjälp av Puppeteer eller Playwright över ett CDP-gränssnitt.
2. Skalbarhet:
Bright Data Scraping Browser lagras på Bright Datas server, som är mycket skalbar. Detta gör den perfekt för växande webbdataskrapningsprojekt.
Med Scraping Browser kan utvecklare lägga till så många webbläsare som de behöver till sina dataskrapningsprojekt utan att behöva bygga ett dyrt system internt.

3. Överlista alla bot-detektionsprogram:
Bot-detekteringssystem blir smartare, vilket gör det svårare och svårare att komma runt dem.
Men Bright Data Scraping Browser använder AI för att automatiskt lära sig hur man tar sig runt dessa system när de förändras, så utvecklare behöver inte ta itu med besväret och kostnaderna för att använda tjänster från tredje part.
Bot-detekteringssystem ser Scraping Browser som en riktig användares webbläsare, vilket gör den lättare att öppna än proxyservrar.
4. Förbi de tuffaste webbplatsblocken:
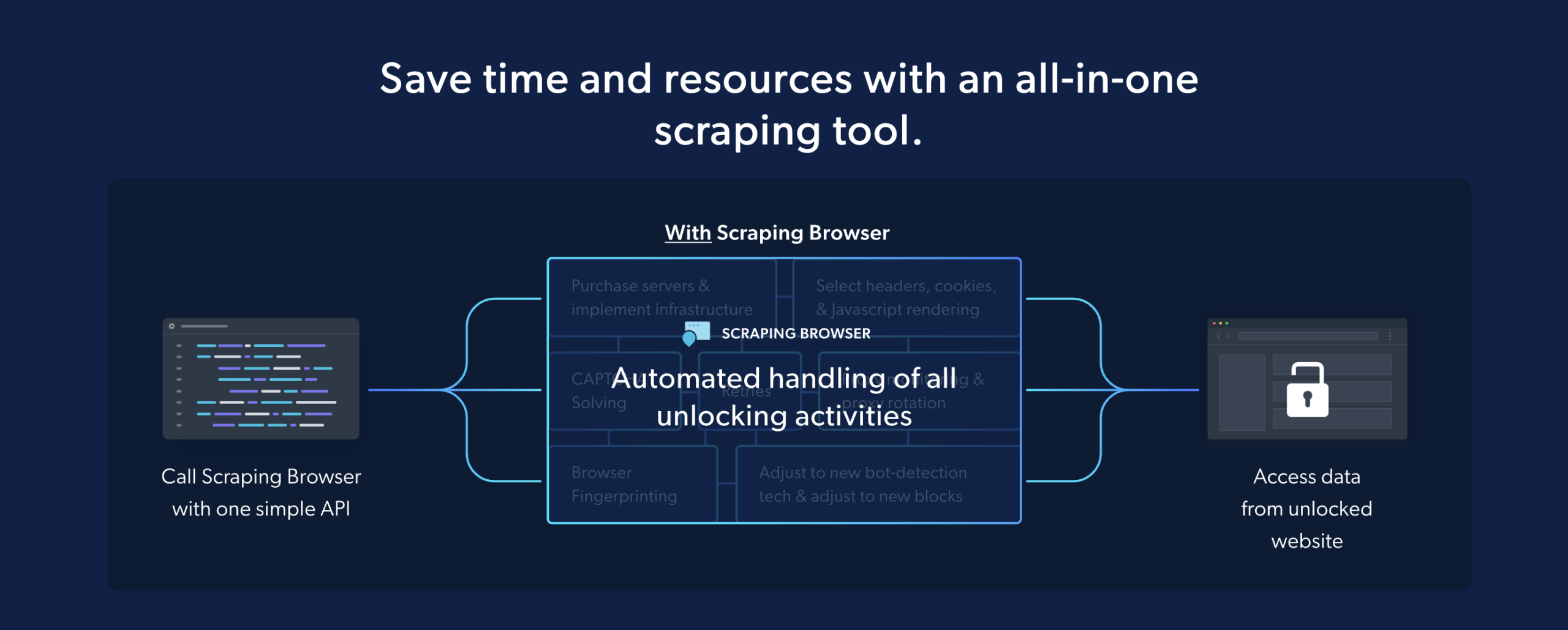
Bright Data Scraping Browser hanterar alla uppgifter för att låsa upp webbplatser direkt bakom kulisserna. Detta inkluderar JavaScript-rendering, cookies, val av data, automatiska återförsök, webbläsarfingeravtryck, CAPTCHA-korrigering och mer.
Det här verktyget sparar utvecklarna mycket tid och pengar, särskilt när de får mycket data och behöver göra komplicerade saker för att öppna den.

Snabblänkar:
- Octoparse-recension: Är det ett riktigt bra verktyg för webbskrapning?
- Wikipedia Web Scraping: Extrahera data för analys
- Bästa webbskrapningstekniker: en praktisk guide
- Netpeak Checker recension
Slutsats: Bright Data Scraping Browser Review 2024
Bright Data Scraping Browser är ett kraftfullt verktyg för dataskrapning som erbjuder en rad funktioner och fördelar för att effektivisera dina skrapningsprojekt.
Med sina effektiva funktioner för avblockering av webbplatser, kompatibilitet med Puppeteer och Playwright, skalbarhet och AI-teknik, kan den här webbläsaren spara tid och resurser samtidigt som den uppnår bättre upplåsningsframgångsfrekvenser än proxyservrar.
Dess automatiska upplåsningsfunktioner för webbplatser gör den också till ett idealiskt verktyg för att skrapa i stor skala, där komplexa upplåsningsoperationer krävs.
Oavsett om du är ett litet företag eller ett stort företag, Bright Data Scraping Browser är ett pålitligt verktyg som kan hjälpa dig att effektivisera dina dataskrapningsoperationer och extrahera värdefulla insikter från internet.