Met online scraping kunt u open gegevens van websites verzamelen voor doeleinden zoals prijsvergelijking, marktonderzoek, advertentieverificatie, enz.
Meestal worden grote hoeveelheden van de benodigde openbare gegevens geëxtraheerd, maar wanneer u tegen blokkades aanloopt, kan de extractie een uitdaging worden.
De beperking kan tariefblokkering of IP-blokkering zijn (het IP-adres van het verzoek is beperkt omdat het afkomstig is uit een verboden gebied, verboden type IP, enz.). (het IP-adres is geblokkeerd omdat het meerdere verzoeken heeft gedaan).

Als je zin hebt om wat nuttige kennis en informatie te verzamelen, dan weet ik zeker dat je hebt overwogen om Wikipedia te schrappen, de kennisencyclopedie die tonnen informatie bevat.
Laten we een paar dingen begrijpen over het webschrapen van Wikipedia.
Wikipedia Webschrapen
Webscraping is een geautomatiseerde methode om gegevens van internet te verzamelen. In dit artikel vindt u diepgaande informatie over webschrapen, een vergelijking met webcrawlen en argumenten voor webschrapen.
Het doel is om gegevens van de Wikipedia-startpagina te verzamelen met behulp van verschillende webscraping-methoden en deze vervolgens te ontleden.
U raakt meer vertrouwd met verschillende webscraping-methoden, Python-webscraping-bibliotheken en procedures voor gegevensextractie en -verwerking.
Webschrapen en Python
Webscraping is in wezen het proces van het extraheren van gestructureerde gegevens uit een grote hoeveelheid gegevens van een groot aantal websites met behulp van software die in een programmeertaal is gemaakt en deze lokaal op onze apparaten opslaat, bij voorkeur in Excel-sheets, JSON of spreadsheets.
Dit helpt programmeurs bij het creëren van logische, begrijpelijke code voor zowel kleine als grote projecten.
Python wordt in de eerste plaats beschouwd als de beste taal voor webscraping. Het kan de meeste webcrawling-gerelateerde taken effectief aan en is meer een alleskunner.
Hoe gegevens van Wikipedia schrapen?
Gegevens kunnen op verschillende manieren uit webpagina's worden gehaald.
U kunt het bijvoorbeeld zelf implementeren met behulp van computertalen zoals Python. Maar tenzij u technisch onderlegd bent, moet u veel studeren voordat u veel met dit proces kunt doen.
Het is ook tijdrovend en kan net zo lang duren als het handmatig doorzoeken van Wikipedia-pagina's. Bovendien zijn gratis webschrapers online toegankelijk. Toch ontbreekt het hen vaak aan betrouwbaarheid en kunnen hun leveranciers duistere bedoelingen hebben.
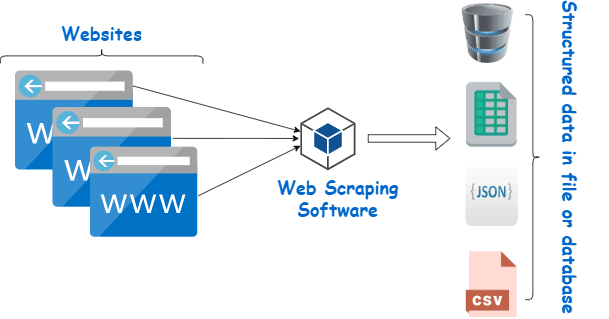
Investeren in een fatsoenlijke webschraper van een gerenommeerde leverancier is de beste methode om Wiki-gegevens te verzamelen.
De volgende stap is meestal eenvoudig en ongecompliceerd omdat de provider u instructies zal geven voor het installeren en gebruiken van de schraper.
Een proxy is een tool die u kunt gebruiken in combinatie met uw wiki-scraper om gegevens effectiever te schrapen. Op Python gebaseerde frameworks zoals Scrapy, Schraaprobot, en Beautiful Soup zijn slechts enkele voorbeelden van hoe gemakkelijk het is om deze taal te gebruiken.
Proxy om gegevens van Wikipedia te schrapen
U hebt proxy's nodig die extreem snel en veilig in gebruik zijn en gegarandeerd niet op u neerkomen wanneer u ze nodig hebt om gegevens effectief te schrapen. Dergelijke proxy's zijn tegen redelijke prijzen verkrijgbaar bij Rayobyte.
We doen ons best om verschillende proxy's aan te bieden, omdat we ons ervan bewust zijn dat elke gebruiker andere voorkeuren en use-cases heeft.
Roterende proxy's voor webscraping Wikipedia
Een instantie van een proxy is er een die zijn IP-adres regelmatig roteert. Om onderbrekingen te voorkomen, wordt ook het IP-adres onmiddellijk gewijzigd wanneer er een ban optreedt. Dit maakt deze specifieke proxy een uitstekende keuze voor het schrapen van sites.
Statische proxy's hebben daarentegen slechts één IP-adres. Als uw internetprovider automatische vervanging niet mogelijk maakt, loopt u tegen een muur aan als u slechts toegang heeft tot één IP-adres en dit wordt geblokkeerd. Hierdoor zijn statische proxy's niet de beste optie voor webschrapen.
Residentiële proxy's voor het webschrapen van Wiki-gegevens
Residentiële proxy's zijn proxy-IP-adressen die internetproviders (ISP's) distribueren en die zijn gekoppeld aan specifieke huishoudens. Omdat ze van echte mensen komen, is het een behoorlijke uitdaging om ze te krijgen. Daardoor zijn ze schaars en relatief duur.

Wanneer u residentiële proxy's gebruikt om gegevens te schrapen, lijkt u een alledaagse gebruiker omdat ze zijn gekoppeld aan de adressen van echte individuen.
Het gebruik van residentiële proxy's verkleint dus aanzienlijk uw kans om ontdekt en geblokkeerd te worden. Het zijn daarom uitstekende kandidaten voor het schrapen van gegevens.
Roterende residentiële proxy's voor het verzamelen van wikigegevens
Een roterende residentiële proxy, die de twee typen combineert waarover we zojuist spraken, is de beste proxy voor webscraping Wikipedia.
U hebt toegang tot een groot aantal thuis-IP's met behulp van een proxy die ze regelmatig roteert.
Dit is van cruciaal belang omdat, ondanks de moeilijkheid om residentiële proxy's te identificeren, het aantal verzoeken dat ze genereren uiteindelijk de aandacht zal trekken van de website die wordt geschraapt.
Roteren zorgt ervoor dat het project door kan gaan, zelfs als het IP-adres onvermijdelijk op de zwarte lijst komt te staan.
Daarom hebben wij wat u nodig heeft, of u nu kiest voor meerdere datacenter-proxy's of liever investeert in een paar residentiële proxy's.
U zult genieten van de beste webscraping-ervaring met proxy's die draaien op 1GBS-snelheid, onbeperkte bandbreedte en XNUMX uur per dag klantenservice.
Je mag ook lezen
- Beste webschraptechnieken: een praktische gids
- Octoparse Review Is het echt een goede tool voor webschrapen?
- Beste tools voor webschrapen
- Wat is webscraping? - Hoe wordt het gebruikt? Hoe het uw bedrijf ten goede kan komen
Waarom zou je Wikipedia schrappen?
Wikipedia is op dit moment een van de meest vertrouwde en informatierijke services in de online wereld. Op bijna alle onderwerpen die je maar kunt bedenken staan op dit platform antwoorden en informatie.
Wikipedia is dus natuurlijk een geweldige bron om gegevens uit te schrapen. Laten we de belangrijkste redenen bespreken waarom u Wikipedia zou moeten schrapen.
Webscraping voor academisch onderzoek
Het verzamelen van gegevens is een van de meest pijnlijke activiteiten van onderzoek. Zoals al besproken, maken webschrapers deze procedure sneller en gemakkelijker, terwijl ze u ook een hoop tijd en energie besparen.
Met een webschraper kunt u snel talloze wikipagina's doorzoeken en alle benodigde gegevens op een georganiseerde manier verzamelen.
Stel even dat het uw doel is om te bepalen of depressie en blootstelling aan zonlicht per land verschillen.
U kunt een Wiki-scraper gebruiken om informatie te vinden zoals de prevalentie van depressie in verschillende landen en hun zonnige uren in plaats van talloze Wikipedia-items te doorlopen.
Reputatie management
Het maken van een Wikipedia-pagina is in de moderne tijd een onmisbare marketingstrategie geworden voor veel verschillende soorten bedrijven, omdat Wikipedia-berichten vaak op de eerste pagina van Google verschijnen.
Maar het hebben van een pagina op Wikipedia zou niet het einde van uw marketinginspanningen moeten zijn. Wikipedia is een crowdsourced platform, dus vandalisme komt nogal vaak voor.
Als gevolg hiervan kan iemand ongunstige informatie aan de pagina van uw bedrijf toevoegen en uw reputatie schaden. Als alternatief kunnen ze uw bedrijf belasteren in een relevant wiki-artikel.
Daarom moet u uw Wiki-pagina in de gaten houden, evenals andere pagina's die uw bedrijf vermelden zodra deze is gemaakt. U kunt dit gemakkelijk doen met behulp van een wiki-scraper.
U kunt periodiek op Wikipedia-pagina's zoeken naar verwijzingen naar uw bedrijf en wijzen op gevallen van vandalisme daar.
Verbeter SEO
U kunt Wikipedia gebruiken om het verkeer naar uw website te vergroten.
Maak een lijst met artikelen die u wilt wijzigen door een Wiki-gegevensschraper te gebruiken om pagina's te vinden die relevant zijn voor uw bedrijf en uw doelgroep.
Begin met het lezen van de artikelen en maak een paar handige aanpassingen om geloofwaardigheid te krijgen als bijdrager aan de site.
Zodra u enige geloofwaardigheid heeft opgebouwd, kunt u verbindingen naar uw website toevoegen op plaatsen waar er verbroken links zijn of waar citaten vereist zijn.
Snelle koppelingen
Python-bibliotheken die worden gebruikt voor webscraping
Python is de meest populaire en gerenommeerde programmeertaal en webscraping-tool ter wereld, zoals al gezegd. Laten we nu eens kijken naar de Python-webscraping-bibliotheken die nu beschikbaar zijn.
Verzoeken (HTTP voor mensen) Bibliotheek voor webscraping
Het wordt gebruikt om verschillende HTTP-verzoeken te verzenden, zoals GET en POST. Van alle bibliotheken is het de meest fundamentele maar ook de meest cruciale.
lxml-bibliotheek voor webscraping
Het lxml-pakket biedt een zeer snelle en krachtige parsing van HTML- en XML-tekst van websites. Dit is degene die u moet kiezen als u van plan bent enorme databases te schrapen.
Prachtige soepbibliotheek voor webscraping
Zijn werk is het bouwen van een ontleedboom voor het ontleden van inhoud. Een geweldige plek om te beginnen voor beginners en is zeer gebruiksvriendelijk.
Seleniumbibliotheek voor webscraping
Deze bibliotheek lost het probleem op dat alle bovengenoemde bibliotheken hebben, namelijk het schrapen van inhoud van dynamisch bevolkte webpagina's.
Het is oorspronkelijk ontworpen voor het geautomatiseerd testen van webapplicaties. Hierdoor is het langzamer en ongeschikt voor taken op industrieel niveau.
Scrapy voor webscraping
Een compleet webscraping-framework dat maakt gebruik van asynchroon gebruik is de BAAS van alle pakketten. Dit verhoogt de efficiëntie en maakt het razendsnel.
Conclusie
Dit was dus vrijwel het belangrijkste aspect dat u moet weten over Wikipedia Web Scraping. Blijf op de hoogte voor meer van dergelijke informatieve berichten over Web Scraping en nog veel meer!
Links


