Tìm kiếm một sự không thiên vị Bright Data Đánh giá trình duyệt cạo, Đừng lo lắng tôi đã bảo vệ bạn.
Quét dữ liệu là một công cụ cần thiết cho các doanh nghiệp và nhà nghiên cứu để trích xuất những hiểu biết có giá trị từ internet.
Tuy nhiên, đây có thể là một nhiệm vụ đầy thách thức và tốn thời gian, đặc biệt khi xử lý các trang web phức tạp sử dụng hệ thống phát hiện bot và khối trang web.
Bright Data Scraping Browser là một trình duyệt tự động tất cả trong một được thiết kế đặc biệt cho mục đích cạo dữ liệu.
Trong bài viết này, chúng tôi sẽ xem xét các các tính năng và lợi ích chính of Bright Data Scraping Browser và giải thích tại sao nó là một công cụ đáng tin cậy cho các dự án cạo dữ liệu.
Cho dù bạn là chủ doanh nghiệp nhỏ hay doanh nghiệp lớn, đánh giá này sẽ giúp bạn xác định liệu Bright Data Scraping Browser là công cụ phù hợp cho nhu cầu cạo dữ liệu của bạn.
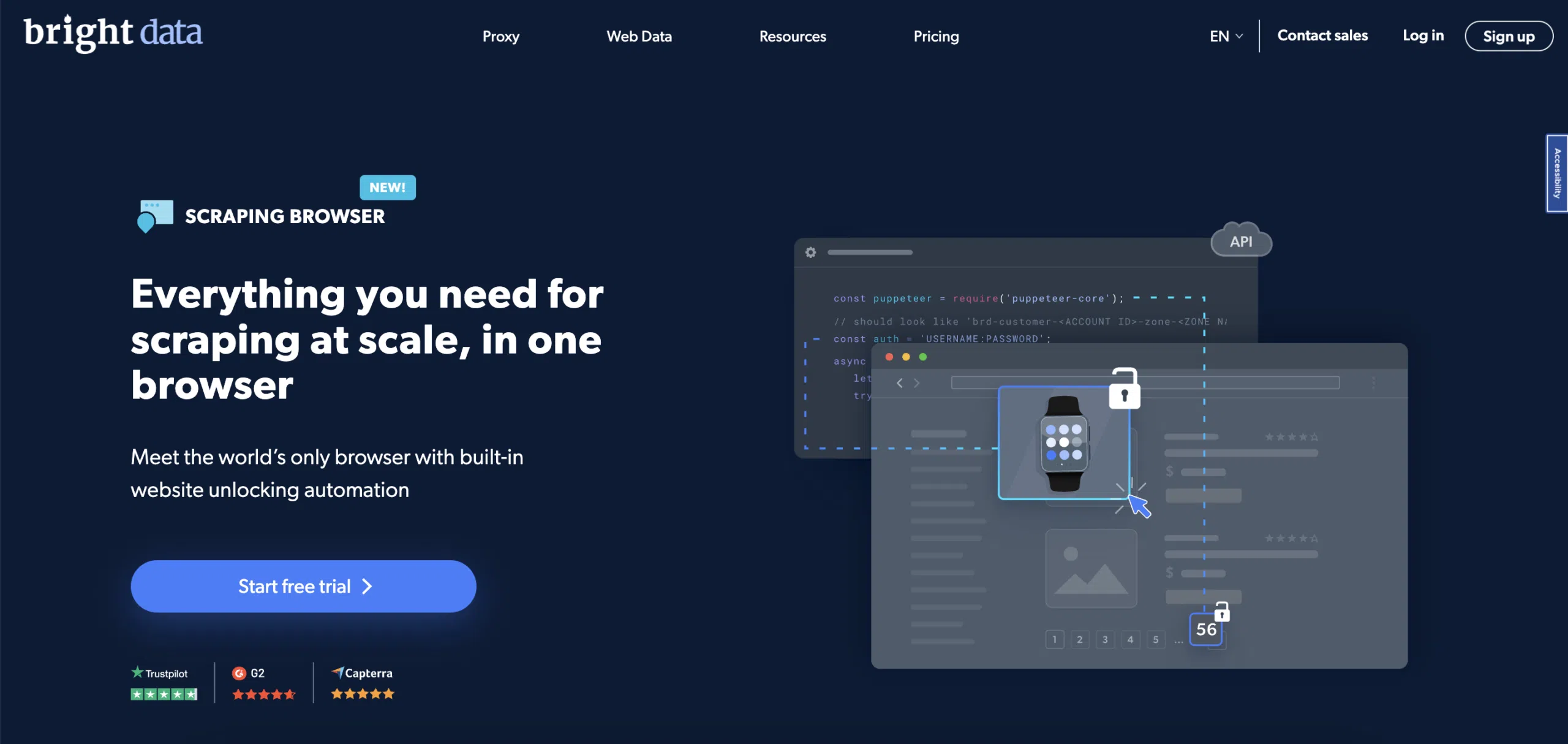
Trình duyệt cạo là gì và tại sao lại sử dụng chúng?

Trình duyệt cạo là một trình duyệt được chạy tự động và được các lập trình viên sử dụng để lấy dữ liệu. Nó có thể được xử lý bởi các API cấp cao như Nghệ sĩ múa rối và nhà viết kịchvà nó có các tính năng tích hợp để bỏ chặn các trang web.
Không giống như các trang web trống, một trình duyệt cạo có một giao diện người dùng đồ họa (GUI) cho phép bạn quyết định cách thức hoạt động của nó.
Khi thu thập dữ liệu, các nhà phát triển sử dụng các trình duyệt tự động khi một trang cần được hiển thị bằng JavaScript hoặc họ cần kết nối với một trang web.
Ví dụ, di chuyển, thay đổi trang, nhấp và thậm chí chụp ảnh màn hình. Ngoài ra, các trình duyệt có thể trợ giúp với các dự án quét dữ liệu quy mô lớn nhắm mục tiêu nhiều trang cùng một lúc.
Scraping Browser là một cách tốt hơn nhiều để mở rộng quy mô các dự án cạo dữ liệu và vượt qua các khối so với các trình duyệt trống. Trình duyệt không đầu là trình duyệt web không có giao diện người dùng hiển thị.
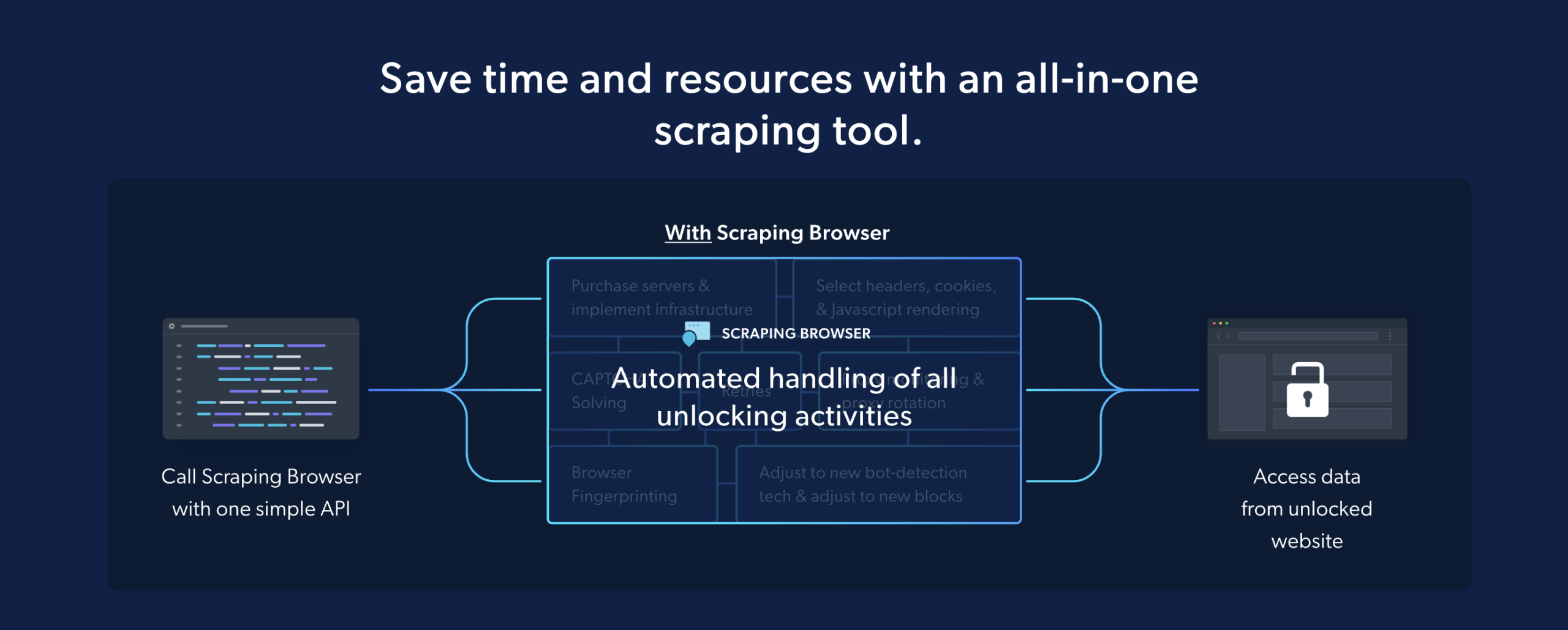
Các trình duyệt này thường được sử dụng với proxy để thu thập dữ liệu, nhưng phần mềm bảo vệ bot có thể dễ dàng phát hiện ra chúng. Điều này gây khó khăn cho việc cạo dữ liệu trên quy mô lớn.
Thực tế là Scraping Browser được mở trên Bright Data'S máy tính là một lợi ích khác. Điều này làm cho nó hoàn hảo cho các dự án cần được mở rộng quy mô.
Các nhà phát triển có thể mở bao nhiêu Trình duyệt cạo tùy thích mà không phải trả tiền cho một hệ thống đắt tiền trên máy tính của họ.
Ngoài ra, Trình duyệt cạo ít có khả năng được tìm thấy bởi phần mềm tìm kiếm bot vì nó có giao diện GUI. Điều này làm cho nó trở thành một công cụ đáng tin cậy hơn cho cạo dữ liệu.


Bright Data Trình duyệt cạo & Hướng dẫn cách mua
Bước - 1: Tới trang web chính thức của Bright Data trình duyệt cạo, cuộn xuống và chọn gói bạn chọn.
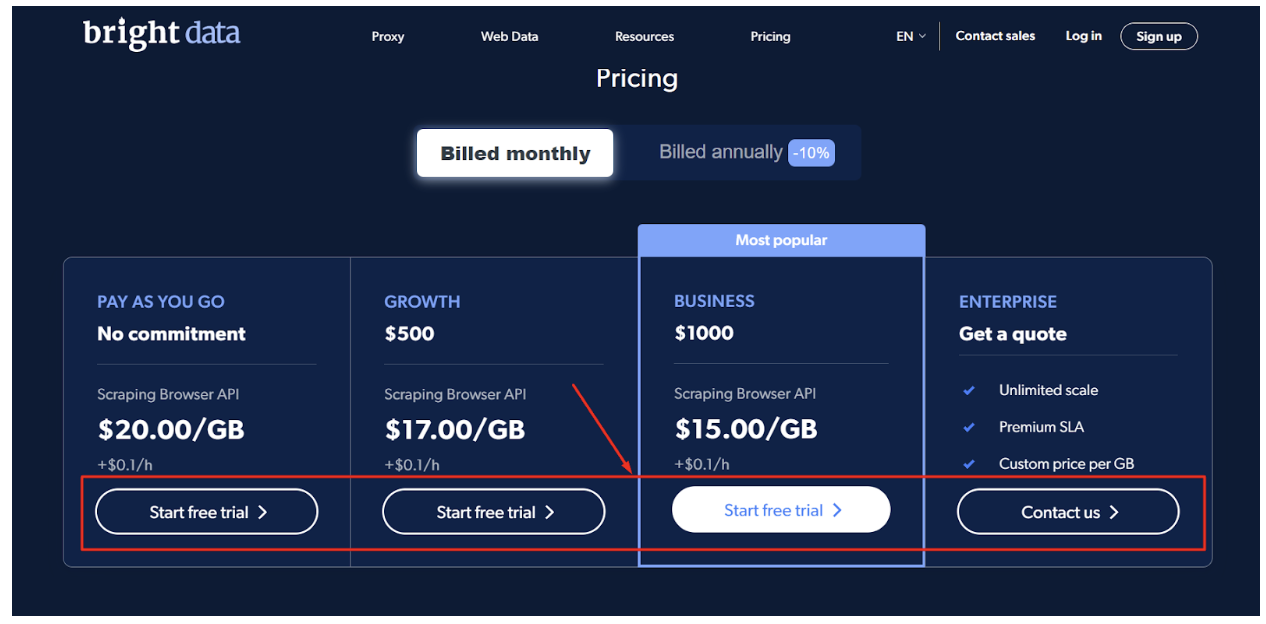
Bước - 2: Điền thông tin chi tiết được yêu cầu, đánh dấu vào ô và nhấp vào 'Tạo tài khoản'.
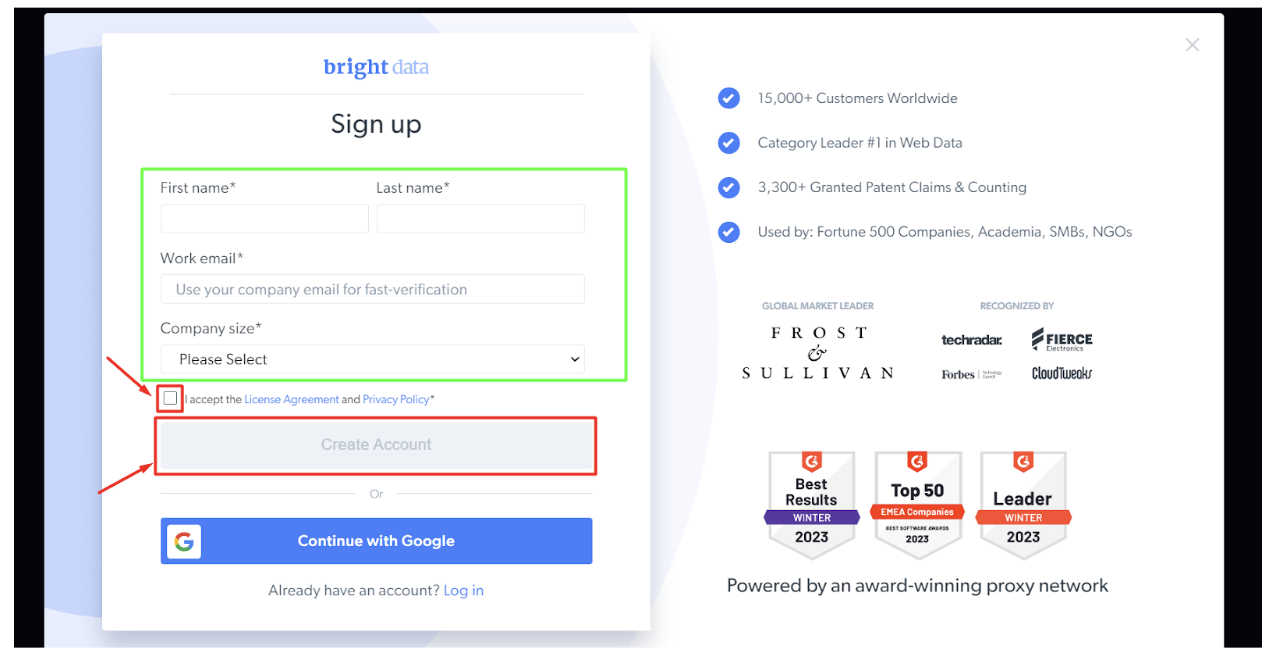
Bước - 3: Điền thông tin chi tiết và nhấp vào 'Đăng ký'.
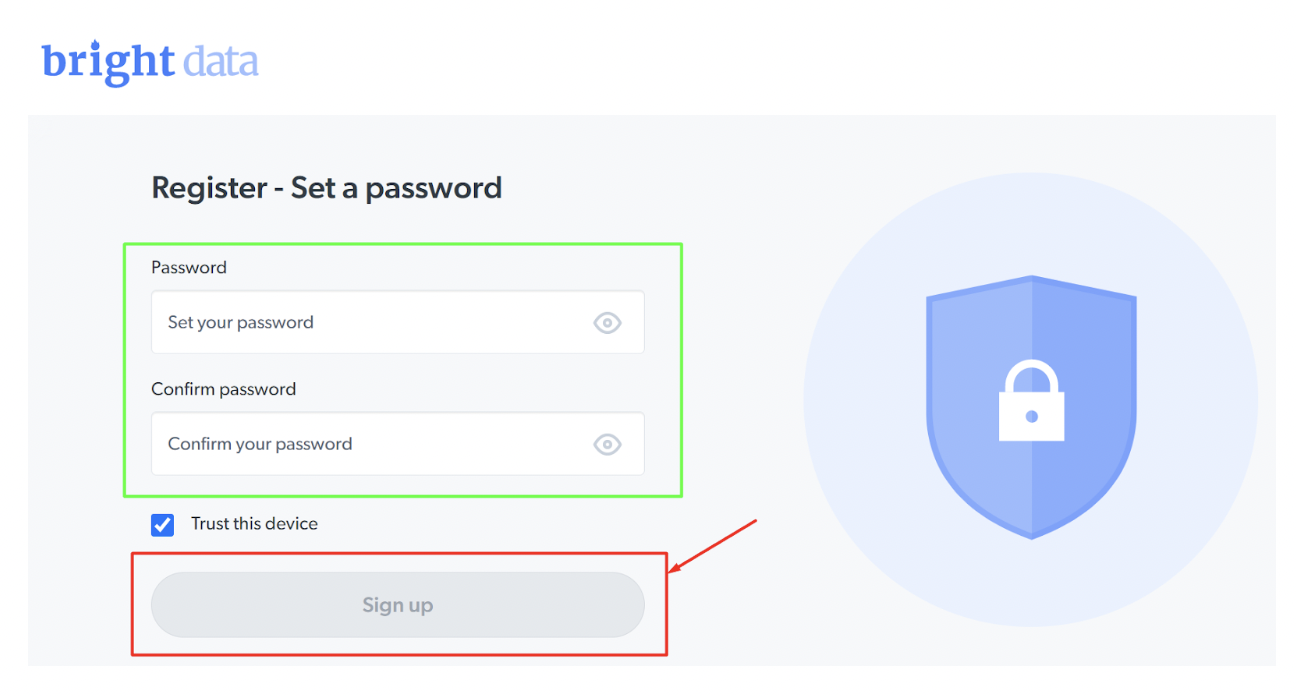
Bước - 4: Nhấp vào 'Bắt đầu' bên dưới Bright Data Trình duyệt cạo.
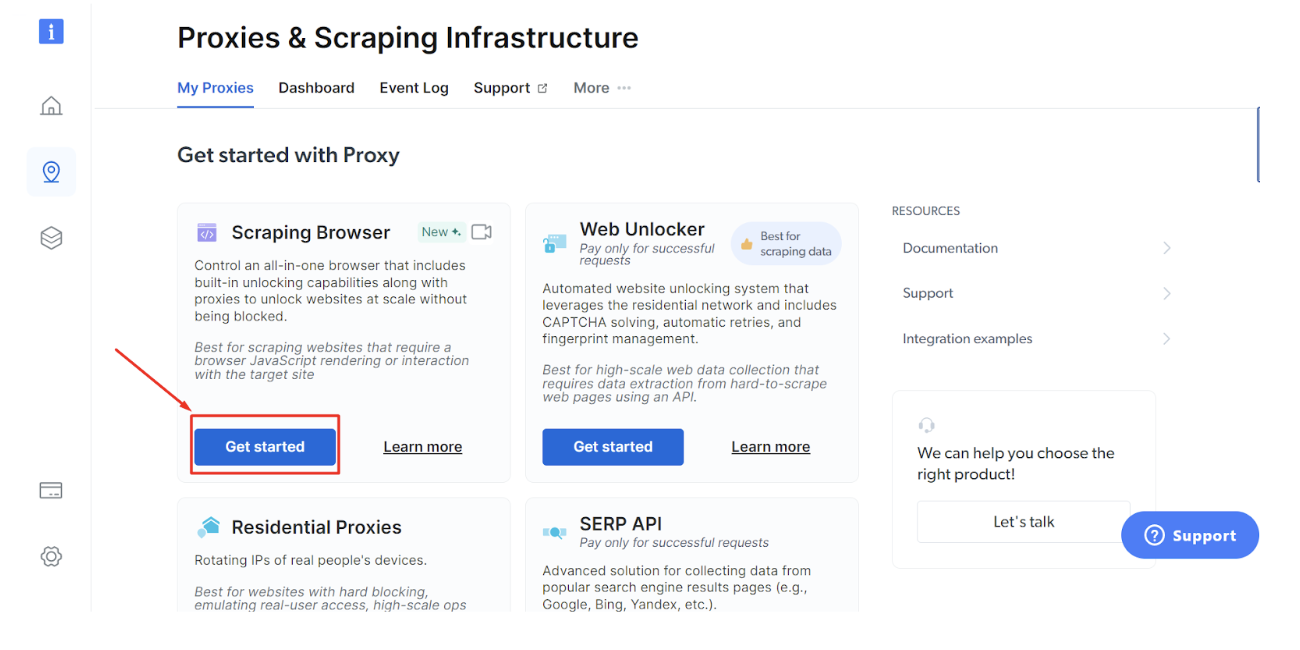
Bước - 5: Nhấp vào 'Lưu và kích hoạt'.

Bước - 6: Điền thông tin thanh toán và nhấp vào 'Lưu địa chỉ'.
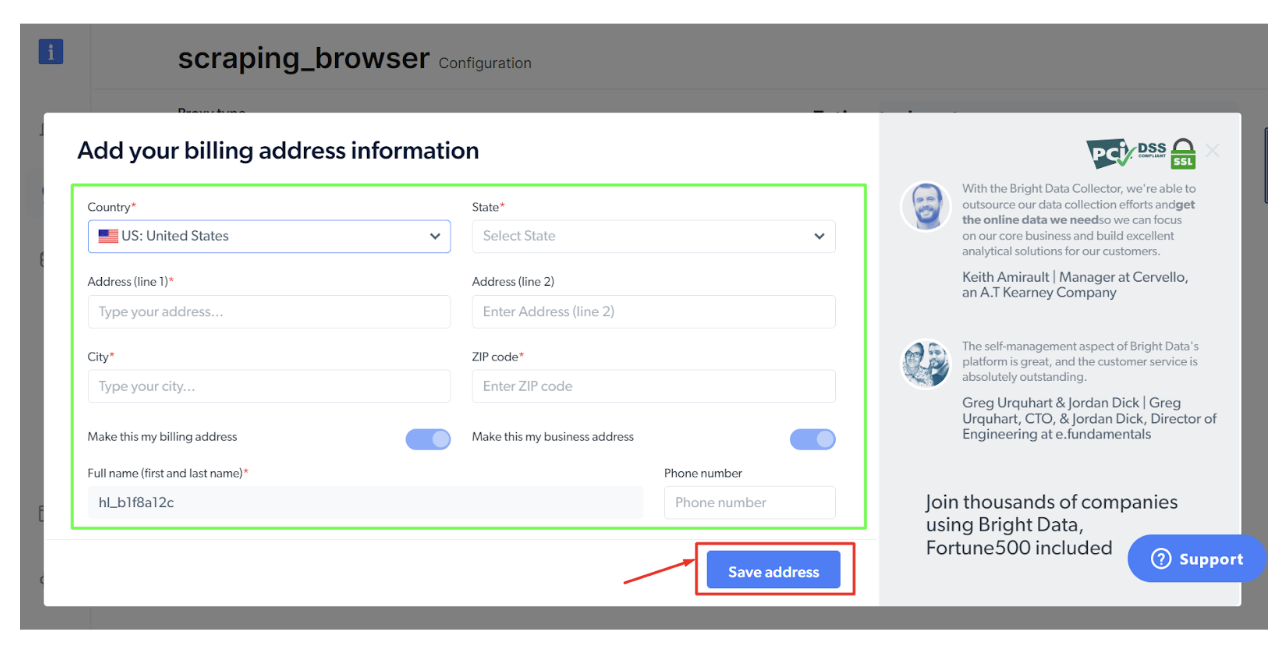
Hoàn tất thanh toán và bạn đã sẵn sàng.
Tại sao tôi khuyên bạn nên sử dụng Bright Data Cạo trình duyệt?
Bright Data Scraping Browser là một trình duyệt tự động được thiết kế dành riêng cho mục đích cạo dữ liệu. Dưới đây là một số lý do tại sao tôi khuyên bạn nên sử dụng trình duyệt này cho dự án thu thập dữ liệu:
1. Tương thích với nghệ sĩ múa rối & nhà viết kịch:
Bright Data Scraping Browser hoạt động với cả Puppeteer (Python) và Playwright (Node.js), đây là hai API phổ biến để tự động hóa việc cạo dữ liệu.
Điều này giúp lập trình viên dễ dàng nhận bất kỳ số lượng phiên trình duyệt nào và làm việc với chúng bằng Puppeteer hoặc Playwright qua giao diện CDP.
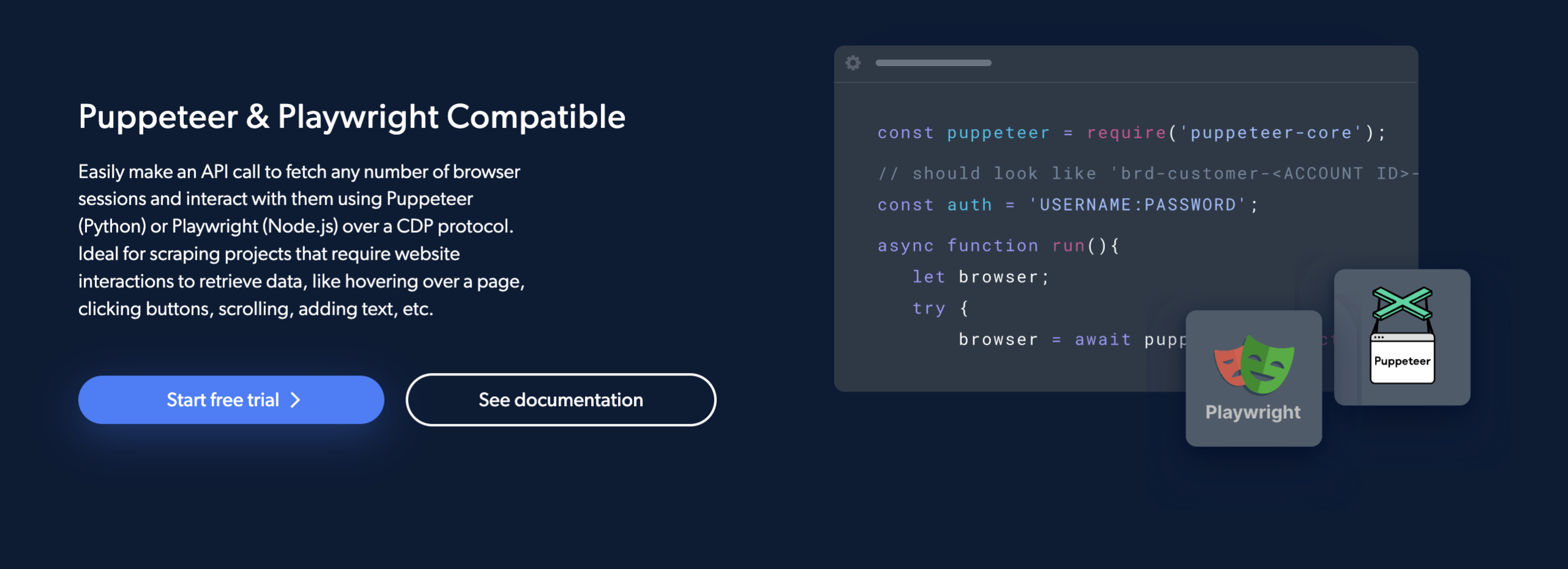
2. Khả năng mở rộng:
Bright Data Scraping Browser được lưu trữ trên Bright Datamáy chủ của nó, rất có khả năng mở rộng. Điều này làm cho nó trở nên hoàn hảo cho các dự án thu thập dữ liệu web đang phát triển.
Với Scraping Browser, các nhà phát triển có thể thêm bao nhiêu trình duyệt họ cần vào các dự án cạo dữ liệu của họ mà không cần phải xây dựng một hệ thống đắt tiền trong nhà.

3. Vượt qua mọi phần mềm phát hiện bot:
Các hệ thống phát hiện bot ngày càng thông minh hơn, điều này khiến việc vượt qua chúng ngày càng khó khăn hơn.
Nhưng Bright Data Scraping Browser sử dụng AI để tự động tìm hiểu cách vượt qua các hệ thống này khi chúng thay đổi, vì vậy các nhà phát triển không phải đối phó với rắc rối và chi phí sử dụng dịch vụ của bên thứ ba.
Các hệ thống phát hiện bot coi Trình duyệt cạo là trình duyệt của người dùng thực, giúp mở dễ dàng hơn so với proxy.
4. Bỏ qua các khối trang web khó khăn nhất:
Bright Data Scraping Browser xử lý tất cả các tác vụ mở khóa trang web ngay lập tức ở hậu trường. Điều này bao gồm kết xuất JavaScript, cookie, chọn dữ liệu, thử lại tự động, lấy dấu vân tay của trình duyệt, sửa CAPTCHA, v.v.
Công cụ này giúp các nhà phát triển tiết kiệm rất nhiều thời gian và tiền bạc, đặc biệt là khi họ nhận được rất nhiều dữ liệu và cần thực hiện những thao tác phức tạp để mở nó.

Liên kết nhanh:
- Đánh giá Octoparse: Công cụ quét web có thực sự tốt không?
- Wikipedia Web Scraping: Trích xuất dữ liệu để phân tích
- Kỹ thuật cạo trang web tốt nhất: Hướng dẫn thực hành
- Đánh giá trình kiểm tra Netpeak
Kết luận: Bright Data Đánh giá trình duyệt Scraping 2024
Bright Data Scraping Browser là một công cụ mạnh mẽ để cạo dữ liệu, cung cấp nhiều tính năng và lợi ích để hợp lý hóa các dự án cạo của bạn.
Với khả năng bỏ chặn trang web hiệu quả, khả năng tương thích với Puppeteer và Playwright, khả năng mở rộng và công nghệ AI, trình duyệt này có thể giúp bạn tiết kiệm thời gian và tài nguyên đồng thời đạt được tỷ lệ mở khóa thành công cao hơn so với proxy.
Khả năng mở khóa trang web tự động của nó cũng làm cho nó trở thành một công cụ lý tưởng để tìm kiếm trên quy mô lớn, nơi yêu cầu các hoạt động mở khóa phức tạp.
Cho dù bạn là chủ doanh nghiệp nhỏ hay doanh nghiệp lớn, Bright Data Scraping Browser là một công cụ đáng tin cậy có thể giúp bạn hợp lý hóa các hoạt động cạo dữ liệu của mình và trích xuất những thông tin chuyên sâu có giá trị từ internet.